深度学习Adam优化算法简介
为你的深度学习模型选择优化算法可能意味着在几分钟、几小时和几天内获得好的结果之间的差异。
Adam优化算法是随机梯度下降算法的扩展,最近在计算机视觉和自然语言处理的深度学习应用中得到了更广泛的采用。
在这篇文章中,你将看到深度学习中使用的Adam优化算法的简单介绍。
读完这篇文章,你就会知道:
- Adam算法是什么,以及使用该方法优化模型的一些好处。
- Adam算法是如何工作的,它与AdaGrad和RMSProp的相关方法有何不同。
- 如何配置Adam算法以及常用的配置参数。
我们开始吧。
Adam优化算法是什么?
Adam是一种基于训练数据迭代更新网络权值的优化算法,可以代替经典的随机梯度下降法。
Adam是由OpenAI的Diederk Kingma和多伦多大学的Jimmy Ba在他们2015年ICLR的论文(海报)中提出的,标题为“Adam:随机优化的方法”。
该算法被称为Adam。它不是首字母缩写,也没有写成“ADAM”。
……Adam这个名字来源于自适应矩估计。
在介绍该算法时,作者列举了使用Adam解决非凸优化问题的吸引人的优点,如下所示:
- 实施起来简单明了。
- 计算效率高。
- 内存需求很小。
- 渐变的对角重缩不变。
- 非常适合于数据和/或参数较大的问题。
- 适用于非固定目标。
- 适用于具有非常噪波/或稀疏渐变的问题。
- 超级参数有直观的解释,通常只需要很少的调整。
Adam是怎么工作的?
Adam不同于经典的随机梯度下降。
随机梯度下降为所有权重更新保持单一的学习率(称为α),并且学习率在训练期间不改变。
为每个网络权重(参数)维护学习率,并且随着学习的展开而单独调整学习率。
该方法根据梯度的一阶和二阶矩的估计来计算不同参数的个体自适应学习率。
作者将Adam描述为结合了随机梯度下降的另外两个扩展的优点。具体而言:
- 自适应梯度算法(AdaGrad),保持每参数学习率,提高稀疏梯度问题(例如自然语言和计算机视觉问题)的性能。
- 均方根传播(RMSProp),它还维护每个参数的学习率,这些学习率基于权重梯度的最近幅度的平均值(例如,它变化的速度)进行调整。这意味着该算法能够很好地处理在线和非平稳问题(例如,噪声)。
Adam认识到AdaGrad和RMSProp的好处。
与RMSProp中基于平均一阶矩(均值)的参数学习率不同,ADAM还利用梯度的二阶矩(未入心方差)的平均值。
具体地说,该算法计算梯度和平方梯度的指数移动平均,并且参数Beta1和Beta2控制这些移动平均的衰减率。
移动平均值的初始值以及Beta1和Beta2的值接近1.0(推荐)会导致矩估计偏向于零。这种偏差是通过先计算有偏估计,然后再计算经偏差校正的估计来克服的。
这篇文章非常易读,如果你对具体的实现细节感兴趣,我鼓励你阅读它。
Adam是有效的
Adam算法是深度学习领域中比较流行的一种算法,因为它能够快速地得到较好的结果。
实证结果表明,Adam方法在实际应用中效果良好,与其他随机优化方法相比具有一定的优势。
在原文中,Adam被实证地证明了收敛符合理论分析的期望。Adam被应用于MNIST数字识别和IMDB情感分析数据集上的Logistic回归算法、MNIST数据集上的多层感知器算法和CIFAR-10图像识别数据集上的卷积神经网络。他们的结论是:
使用大型模型和数据集,我们证明Adam可以有效地解决实际的深度学习问题。
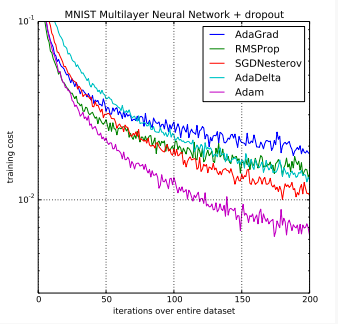 训练多层感知器的Adam算法与其他优化算法的比较
训练多层感知器的Adam算法与其他优化算法的比较塞巴斯蒂安·鲁德(Sebastian Ruder)对现代梯度下降优化算法进行了全面的评论,题为“梯度下降优化算法概述”,首先作为博客文章发表,然后在2016年发布了一份技术报告。
这篇论文基本上是对现代方法的一次介绍。在标题为“使用哪个优化器?”的小节中,他推荐使用Adam。
就目前而言,RMSprop、Adadelta和Adam是非常相似的算法,它们在类似的环境中表现良好……当梯度变得更稀疏时,它的偏差校正有助于Adam在接近优化结束时略微优于RMSprop。就目前而言,Adam可能是最好的整体选择。
在安德烈·卡帕西等人开发的斯坦福大学计算机视觉深度学习课程“CS231n:用于视觉识别的卷积神经网络”中,Adam算法再次被建议为深度学习应用的默认优化方法。
实际上,目前推荐使用Adam作为默认算法,并且通常比RMSProp稍好一些。然而,通常也值得尝试SGD+Nesterov Momentum作为替代方案。
后来说得更清楚了:
推荐使用的两个更新是SGD+Nesterov Momentum或Adam。
Adam正在被改编成深度学习论文中的基准。
例如,它被用在关于图像字幕注意的论文《显示、注意和讲述:具有视觉注意的神经图像字幕生成》和关于图像生成的《绘制:用于图像生成的递归神经网络》的论文中。
Adam配置参数
- alpha。也称为学习速率或步长。权重更新的比例(例如0.001)。值越大(例如0.3),更新速率之前的初始学习速度越快。较小的值(例如1.0E-5)会降低培训期间的学习速度。
- beta1。一阶矩的指数衰减率估计值(例如0.9)。
- beta2。二阶矩估计的指数衰减率(例如0.999)。对于具有稀疏渐变的问题(例如,NLP和计算机视觉问题),该值应设置为接近1.0。
- epsilon。是一个非常小的数字,以防止实现中的任何被零除(例如10E-8)。
此外,学习速率衰减也可以与Adam一起使用。本文用衰减率alpha = alpha/sqrt(t)对每个epoch (t) 进行Logistic回归论证。
Adam的论文建议:
测试的机器学习问题的良好默认设置是alpha=0.001、beta1=0.9、beta2=0.999和epsilon=10−8。
TensorFlow文档建议对epsilon进行一些调整:
通常,epsilon的默认值1e-8可能不是好的默认值。例如,在ImageNet上训练“盗梦空间”网络时,当前较好的选择是1.0或0.1。
我们可以看到,目前流行的深度学习库普遍使用论文推荐的默认参数。
- TensorFlow: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08.
- Keras: lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0.
- Blocks: learning_rate=0.002, beta1=0.9, beta2=0.999, epsilon=1e-08, decay_factor=1.
- Lasagne: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- Caffe: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- MxNet: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
- Torch: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
进一步阅读
本节列出了解有关ADAM优化算法的更多信息的资源。
- Adam:一种随机优化方法,2015。
- 维基百科上的随机梯度下降。
- 2016梯度下降优化算法综述。
- Adam:一种随机优化方法(综述)。
- 深度网络优化(幻灯片)。
- Adam:一种随机优化方法(幻灯片)。
总结
在这篇文章中,你发现了深度学习的Adam优化算法。
具体地说,你了解到:
- Adam是一种用于训练深度学习模型的随机梯度下降的替换优化算法。
- Adam结合了AdaGrad和RMSProp算法的最佳特性,提供了一种可以处理噪声问题上的稀疏梯度的优化算法。
- Adam相对容易配置,默认配置参数可以很好地解决大多数问题。

