如何从头开始开发CIFAR-10照片分类的CNN
CIFAR-10小照片分类问题是用于计算机视觉和深度学习的标准数据集。
虽然数据集得到了有效的解决,但它可以作为学习和实践如何从头开始开发、评估和使用卷积深度学习神经网络进行图像分类的基础。
这包括如何开发健壮的测试工具来评估模型的性能,如何探索对模型的改进,以及如何保存模型并在以后加载它以对新数据进行预测。
在本教程中,你将了解如何从头开始开发用于对象照片分类的卷积神经网络模型。
完成本教程后,你将了解:
- 如何开发测试工具来开发模型的健壮评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以提高学习和建模能力。
- 如何开发最终的模型,评估最终模型的性能,并使用它对新图像进行预测。
我们开始吧。
教程概述
本教程分为六个部分,它们是:
- CIFAR-10照片分类数据集。
- 模型评估测试线束。
- 如何开发基线模型。
- 如何开发一种改进的模型。
- 如何进一步改进。
- 如何最终确定模型并做出预测。
CIFAR-10照片分类数据集
CIFAR是加拿大高级研究院的缩写,CIFAR-10数据集是由CIFAR研究所的研究人员与CIFAR-100数据集一起开发的。
该数据集由来自10个类别(例如青蛙、鸟类、猫、船只等)的60,000张32×32像素的对象彩色照片组成。类别标签及其标准关联整数值如下所示。
- 0:飞机。
- 1:汽车。
- 2:鸟。
- 3:猫。
- 4:鹿。
- 5:狗。
- 6:青蛙。
- 7:马。
- 8:船舶。
- 9:卡车。
这些都是非常小的图像,比一张典型的照片要小得多,而且数据集是用于计算机视觉研究的。
CIFAR-10是一个广为人知的数据集,广泛用于机器学习领域的计算机视觉算法基准测试。问题已经“解决”了。达到80%的分类准确率是比较简单的。深度学习卷积神经网络在测试数据集上的分类正确率在90%以上,取得了较好的性能。
下面的示例使用Kera API加载CIFAR-10数据集,并创建训练数据集中前九个图像的绘图。
# example of loading the cifar10 dataset
from matplotlib import pyplot
from keras.datasets import cifar10
# load dataset
(trainX, trainy), (testX, testy) = cifar10.load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(trainX[i])
# show the figure
pyplot.show()
运行该示例将加载CIFAR-10训练和测试数据集,并打印它们的形状。
我们可以看到,在训练数据集中有50,000个示例,在测试数据集中有10,000个示例,并且图像确实是正方形的,具有32×32像素和颜色,具有三个通道。
Train: X=(50000, 32, 32, 3), y=(50000, 1) Test: X=(10000, 32, 32, 3), y=(10000, 1)
还创建了数据集中前九个图像的曲线图。很明显,与现代照片相比,这些图像确实非常小;在分辨率极低的情况下,要想看到一些图像到底代表了什么是一件很有挑战性的事情。
这种低分辨率很可能是顶级算法在数据集上实现的性能有限的原因。
 CIFAR-10数据集中图像子集的绘制
CIFAR-10数据集中图像子集的绘制模型评估测试线束
CIFAR-10数据集可以作为开发和实践使用卷积神经网络解决图像分类问题的方法的有用起点。
我们可以从头开始开发一个新的模型,而不是查看关于数据集上性能良好的模型的文献。
数据集已经有了我们将使用的定义良好的训练和测试数据集。另一种选择可能是在k=5或k=10的情况下执行k重交叉验证。如果有足够的资源,这是可取的。在这种情况下,为了确保本教程中的示例在合理的时间内执行,我们将不使用k-折交叉验证。
测试工具的设计是模块化的,我们可以为每个部件开发单独的功能。如果我们愿意,这允许修改或互换测试工具的给定方面,与其他方面分开。
我们可以用五个关键要素来开发这个测试工具。它们是数据集的加载、数据集的准备、模型的定义、模型的评估和结果的呈现。
加载数据集
我们知道一些关于数据集的事情。
例如,我们知道图像都是预先分割的(例如,每个图像都包含单个对象),图像都具有32×32像素的相同正方形大小,并且图像是彩色的。因此,我们几乎可以立即加载图像并使用它们进行建模。
# load dataset (trainX, trainY), (testX, testY) = cifar10.load_data()
我们还知道有10个类,并且类被表示为唯一的整数。
因此,我们可以对每个样本的类元素使用1热编码,将整数转换为10个元素的二进制向量,类值的索引为1。我们可以使用to_categorical()实用函数来实现这一点。
# one hot encode target values trainY = to_categorical(trainY) testY = to_categorical(testY)
load_dataset()函数实现这些行为,并可用于加载数据集。
# load train and test dataset def load_dataset(): # load dataset (trainX, trainY), (testX, testY) = cifar10.load_data() # one hot encode target values trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY
准备像素数据
我们知道数据集中每个图像的像素值都是介于无颜色和全彩色之间或0和255之间的无符号整数。
我们不知道缩放建模像素值的最佳方式,但我们知道需要一些缩放。
一个好的起点是规格化像素值,例如将它们重新缩放到范围[0,1]。这包括首先将数据类型从无符号整数转换为浮点数,然后将像素值除以最大值。
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
下面的prep_pixels()函数实现这些行为,并为需要缩放的训练和测试数据集提供像素值。
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
在任何建模之前,必须调用此函数来准备像素值。
定义模型
接下来,我们需要一种建立神经网络模型的方法。
下面的define_model()函数将定义并返回该模型,并且可以为我们希望稍后评估的给定模型配置填充或替换该模型。
# define cnn model def define_model(): model = Sequential() # ... return model
评估模型
在定义了模型之后,我们需要对其进行拟合和评估。
拟合模型将需要指定训练周期数和批次大小。目前,我们将使用通用的100个培训周期和64个适度的批次大小。
最好使用单独的验证数据集,例如通过将训练数据集分割成训练集和验证集。在这种情况下,我们不会拆分数据,而是使用测试数据集作为验证数据集,以保持示例的简单性。
测试数据集可以像验证数据集一样使用,并在每个训练周期结束时进行评估。这将在列车和测试数据集上跟踪每个时段的模型评估分数,稍后可以绘制这些分数。
# fit model history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
一旦模型合适,我们就可以直接在测试数据集上对其进行评估。
# evaluate model _, acc = model.evaluate(testX, testY, verbose=0)
目前的结果
一旦对模型进行了评估,我们就可以展示结果了。
提出了两个关键问题:模型在训练过程中学习行为的诊断和模型性能的估计。
首先,诊断包括创建线条图,显示培训期间列车和测试集上的模型性能。这些曲线图对于了解模型是否过度拟合、不足拟合或是否与数据集很好拟合很有价值。
我们将创建一个包含两个子图的单个图形,一个用于损失,另一个用于精度。蓝线将指示训练数据集上的模型性能,橙线将指示坚持测试数据集上的性能。下面的summarize_diagnostics()函数根据收集的训练历史创建并显示此图。绘图将保存到文件中,特别是与扩展名为‘png’的脚本同名的文件。
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
接下来,我们可以报告测试数据集的最终模型性能。
这可以通过直接打印分类精度来实现。
print('> %.3f' % (acc * 100.0))
完整示例
我们需要一个函数来驱动测试工具。
这涉及到调用所有定义函数。下面的run_test_harness()函数实现了这一点,可以调用它来启动对给定模型的评估。
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
现在我们已经拥有了测试工具所需的一切。
下面列出了CIFAR-10数据集的测试工具的完整代码示例。
# test harness for evaluating models on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
# ...
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
这个测试工具可以评估我们希望在CIFAR-10数据集上评估的任何CNN模型,并且可以在CPU或GPU上运行。
注意:按照原样,没有定义任何模型,因此这个完整的示例不能运行。
接下来,让我们看看如何定义和评估基线模型。
如何开发基线模型
我们现在可以研究CIFAR-10数据集的基线模型。
基线模型将建立我们所有其他模型可以与之比较的最低模型性能,以及我们可以用作研究和改进基础的模型体系结构。
VGG模型的一般体系结构原则是一个很好的起点。这些都是一个很好的起点,因为它们在ILSVRC 2014大赛中取得了最佳性能,而且架构的模块化结构易于理解和实现。有关VGG模型的更多详细信息,请参阅2015年的论文“用于大规模图像识别的甚深卷积网络”。
该体系结构包括用小的3×3滤波器堆叠卷积层,然后是最大汇聚层。这些层一起形成一个块,并且可以重复这些块,其中每个块中的滤波器的数量随着网络的深度而增加,例如模型的前四个块的32、64、128、256。在卷积层上使用填充,以确保输出特征图的高度和宽度与输入匹配。
我们可以在CIFAR-10问题上探索此体系结构,并将模型与此体系结构进行1、2和3个块的比较。
每一层都将使用ReLU激活功能和权重初始化,它们通常是最佳实践。例如,可以在Keras中定义3块VGG样式的架构,如下所示:
# example of a 3-block vgg style architecture model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) ...
这定义了模型的特征检测器部分。这必须与模型的分类器部分相结合,该分类器部分解释特征并预测给定照片属于哪一类。
这可以针对我们调查的每个模型进行修复。首先,必须拼合从模型的特征提取部分输出的特征地图。然后,我们可以用一个或多个完全连接的层来解释它们,然后输出预测。对于这10个类,输出层必须有10个节点,并使用softmax激活功能。
# example output part of the model model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) ...
模型将采用随机梯度下降法进行优化。
我们会用0.001的适度学习率和0.9%的大势头,这两个都是很好的一般起点。该模型将优化多类分类所需的分类交叉熵损失函数,并监测分类精度。
# compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
我们现在有足够的元素来定义VGG样式的基线模型。我们可以使用1、2和3个VGG模块定义三个不同的模型体系结构,这需要定义3个独立版本的define_model()函数,如下所示。
要测试每个模型,必须创建一个新脚本(例如,model_baseline1.py、model_baseline2.py…)。使用上一节中定义的测试工具,以及下面定义的新版本的define_model()函数。
让我们依次查看每个define_model()函数和结果测试工具的求值。
基线:1个VGG块
下面列出了一个VGG块的define_model()函数
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
在测试工具中运行模型时,首先在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们可以看到该模型实现了略低于70%的分类准确率。
> 67.070
创建一个图形并将其保存到文件中,该图形显示了在训练和测试数据集上训练期间模型的学习曲线,这两者都与损失和准确性有关。
在这种情况下,我们可以看到模型很快就不适合测试数据集了。这一点很清楚,如果我们查看损失图(顶部图),我们可以看到模型在训练数据集(蓝色)上的性能继续改善,而在测试数据集(橙色)上的性能改善,然后在大约15个时期开始变差。
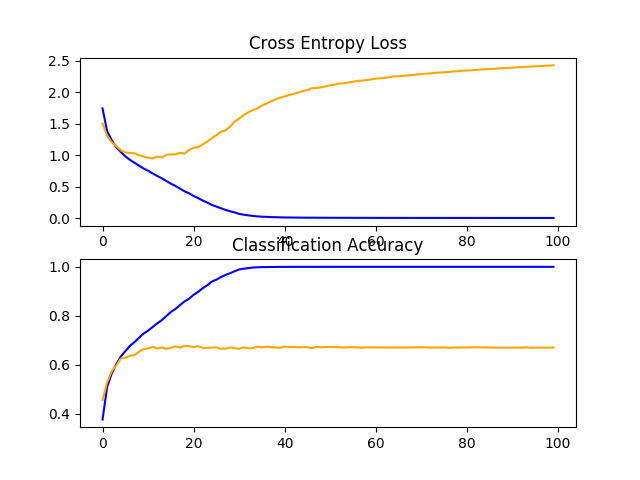 CIFAR-10数据集上VGG-1基线学习曲线的直线图
CIFAR-10数据集上VGG-1基线学习曲线的直线图基准:2个VGG块
下面列出了两个VGG块的define_model()函数。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
在测试工具中运行模型时,首先在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在本例中,我们可以看到具有两个块的模型比具有单个块的模型执行得更好:这是一个好兆头。
> 71.080
将创建一个显示学习曲线的图形并将其保存到文件中。在这种情况下,我们继续看到严重的过度匹配。
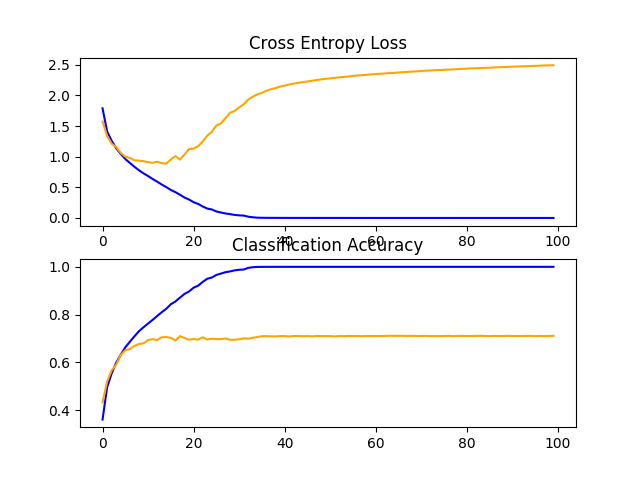 CIFAR-10数据集上VGG 2基线学习曲线的直线图
CIFAR-10数据集上VGG 2基线学习曲线的直线图基准:3个VGG块
下面列出了三个VGG块的define_model()函数。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
在测试工具中运行模型时,首先在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,随着模型深度的增加,性能会有另一次适度的提高。
> 73.500
回顾一下显示学习曲线的数字,我们再次看到在前20个训练时期内发生了戏剧性的过度匹配。
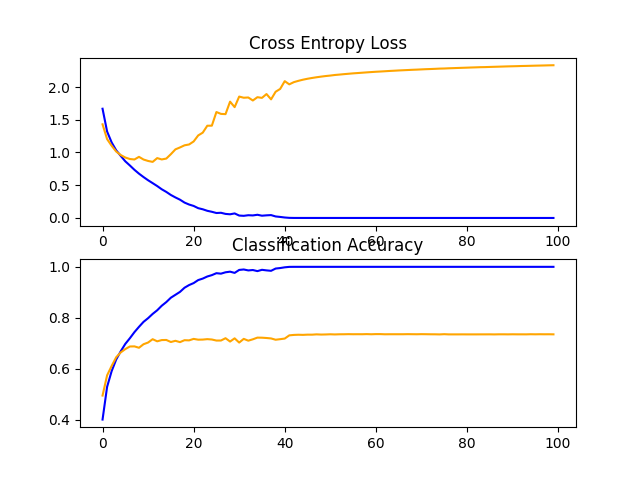 CIFAR-10数据集上VGG 3基线学习曲线的直线图
CIFAR-10数据集上VGG 3基线学习曲线的直线图讨论
我们使用基于VGG的架构探索了三种不同的模型。
结果可以总结如下,尽管考虑到算法的随机性,我们必须假设这些结果有一些差异:
- VGG1:67.070%。
- VGG2:71.080%。
- VGG3:73.500%。
在所有情况下,模型都能够学习训练数据集,显示出对训练数据集的改进,至少持续了40个时代,甚至更多。这是一个好兆头,因为它表明问题是可学习的,并且所有三个模型都有足够的学习问题的能力。
模型在测试数据集上的结果表明,随着模型深度的增加,分类精度也随之提高。如果对具有四层和五层的模型进行评估,这种趋势可能会继续下去,这可能会是一个有趣的扩展。然而,在大约15到20个时代,所有三个模型都显示出相同的戏剧性过度拟合模式。
这些结果表明,有三个VGG区块的模型是我们研究的一个很好的起点或基线模型。
结果还表明,该模型需要进行正则化处理,以解决测试数据集的快速过拟合问题。更广泛地说,结果表明,研究减缓模型收敛(学习速度)的技术可能是有用的。这可能包括诸如数据增强以及学习速率计划、更改批大小等技术。
在下一节中,我们将研究其中一些改进模型性能的想法。
如何开发一种改进的模型
现在我们已经建立了基准模型,即具有三个块的VGG体系结构,我们可以调查对模型和训练算法的修改,以寻求提高性能。
我们将首先看两个主要领域来解决观察到的严重过拟合问题,即正则化和数据增强。
正则化技术
我们可以尝试许多正则化技术,尽管观察到的过拟合的性质表明,也许提前停止是不合适的,而减缓收敛速度的技术可能是有用的。
我们将研究辍学和权重规则化或权重衰减的效果。
丢弃正则化
丢弃是一种简单的技术,它会随机将节点从网络中丢弃。它具有规则化效果,因为剩余节点必须适应以拾取被移除节点的闲置。
有关丢弃的更多信息,请参见帖子:
可以通过添加新的丢弃层将丢弃添加到模型中,其中删除的节点量指定为参数。根据在模型中的什么位置添加层和使用多少丢弃,有许多模式可以将丢弃添加到模型中。
在这种情况下,我们将在每个最大池层和完全连接的层之后添加丢弃层,并使用20%的固定丢失率(例如,保留80%的节点)。
下面列出了具有丢弃的更新的VGG 3基准模型。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
为了完整起见,下面提供了完整的代码清单。
# baseline model with dropout on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们可以看到分类准确率从未丢弃的约73%跃升到丢弃的约83%,增幅约为10%。
> 83.450
回顾模型的学习曲线,我们可以看到已经解决了过拟合问题。该模型在大约40或50个时期内收敛良好,在这一点上,测试数据集没有进一步的改进。
这是一个很棒的结果。我们可以详细说明这个模型,并以大约10个时期的耐心添加提前停止,以在训练期间在没有观察到进一步改进的点附近将性能良好的模型保存在测试集上。
我们还可以尝试探索一种学习速率时间表,该时间表在改进测试集停滞后降低学习速率。
丢弃的表现很好,我们不知道20%的选择比率是最好的。我们可以探索其他丢弃率,以及模型体系结构中退出层的不同位置。
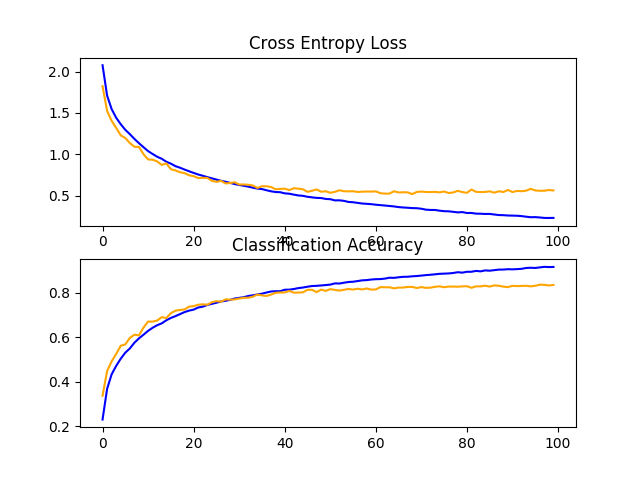 CIFAR-10数据集上带丢包基线模型学习曲线的直线图
CIFAR-10数据集上带丢包基线模型学习曲线的直线图重量衰减
权重正则化或权重衰减涉及更新损失函数以与模型权重的大小成比例地惩罚模型。
这具有正则化效果,因为较大的权重会导致更复杂且不太稳定的模型,而较小的权重通常更稳定且更一般。
要了解有关体重规则的更多信息,请参见文章:
我们可以通过定义“kernel_regularizer”参数和指定正则化的类型来向卷积层和完全连通层添加权重正则化。在本例中,我们将使用L2权重正则化,这是神经网络最常用的类型,合理的默认权重为0.001。
下面列出了具有权重衰减的更新基线模型。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001), input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform', kernel_regularizer=l2(0.001))) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
为了完整起见,下面提供了完整的代码清单。
# baseline model with weight decay on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.regularizers import l2
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001), input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform', kernel_regularizer=l2(0.001)))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将打印测试数据集的分类准确性。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们在测试集上没有看到模型性能的提高;事实上,我们看到性能从大约73%下降到大约72%。
> 72.550
回顾学习曲线,我们确实看到过度适应的情况略有减少,但其影响不如辍学那么有效。
我们或许可以通过使用更大的权重(例如0.01甚至0.1)来改善权重衰减的效果。
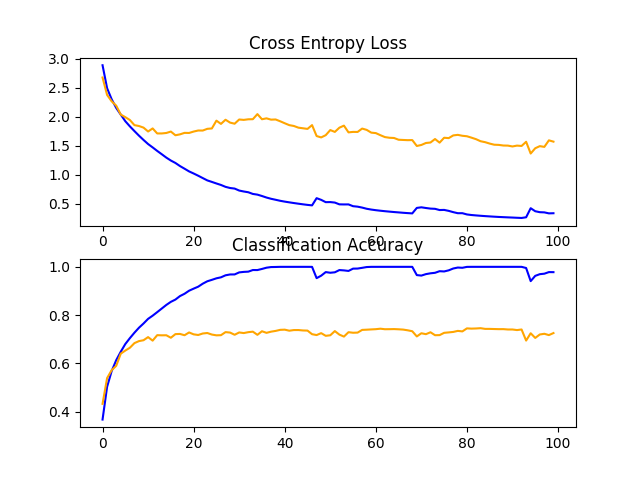 CIFAR-10数据集上权值衰减基线模型学习曲线的直线图
CIFAR-10数据集上权值衰减基线模型学习曲线的直线图数据增强
数据扩充涉及通过小的随机修改来复制训练数据集中的示例。
这具有规则化效果,因为它既扩展了训练数据集,又允许模型学习相同的一般特征,尽管是以更一般化的方式。
可以应用多种类型的数据增强。考虑到数据集由对象的小照片组成,我们不希望使用过度扭曲图像的增强,以便可以保留和使用图像中的有用特征。
可能有用的随机放大类型包括水平翻转、图像的微小移位,以及可能对图像的小缩放或小裁剪。
我们将研究简单的增强对基线图像的影响,特别是图像高度和宽度的水平翻转和10%的移位。
这可以使用ImageDataGenerator类在Keras中实现;例如:
# create data generator datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # prepare iterator it_train = datagen.flow(trainX, trainY, batch_size=64)
这可以在训练期间使用,方法是将迭代器传递给mod.fit_generator()函数并定义单个纪元中的批次数量。
# fit model steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0)
不需要对模型进行任何更改。
下面列出了支持数据增强的run_test_harness()函数的更新版本。
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# create data generator
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# prepare iterator
it_train = datagen.flow(trainX, trainY, batch_size=64)
# fit model
steps = int(trainX.shape[0] / 64)
history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
为了完整起见,下面提供了完整的代码清单。
# baseline model with data augmentation on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# create data generator
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# prepare iterator
it_train = datagen.flow(trainX, trainY, batch_size=64)
# fit model
steps = int(trainX.shape[0] / 64)
history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们看到模型性能的另一个重大改进,就像我们看到的辍学一样。在这种情况下,从基线模型的约73%提高到约84%,提高了约11%。
> 84.470
回顾学习曲线,我们看到模型性能的改善与辍学类似,尽管损失图表明,测试集上的模型性能可能比辍学的停滞时间略早。
结果表明,同时使用丢弃和数据增强的配置可能是有效的。
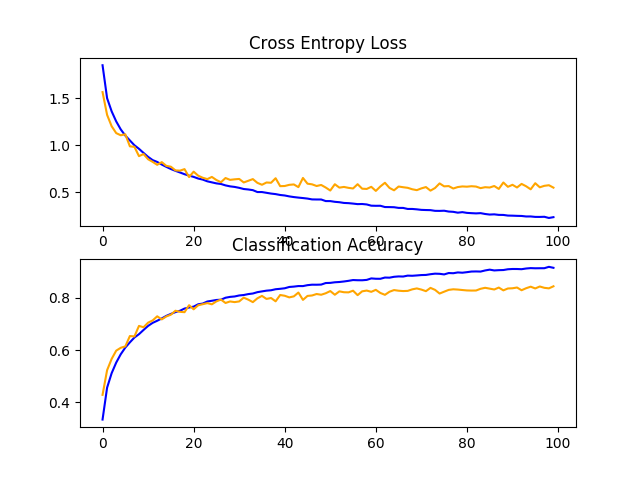 CIFAR-10数据集上数据增强基线模型学习曲线的直线图
CIFAR-10数据集上数据增强基线模型学习曲线的直线图讨论
在本节中,我们探索了三种旨在减缓模型收敛速度的方法。
以下是调查结果的摘要:
- 基线+丢失率:83.450%。
- 基线+权重衰减:72.550%。
- 基线+数据增强:84.470%。
结果表明,丢弃和数据增强都有预期的效果,而重量衰减,至少对于所选的配置来说,没有达到预期的效果。
既然模型已经很好地学习了,我们就可以寻找关于什么是工作的改进,以及什么是工作的组合。
如何进一步改进
在上一节中,我们发现,当添加到基线模型中时,辍学和数据增强会导致模型很好地学习问题。
我们现在将研究这些技术的改进,看看是否可以进一步提高模型的性能。具体地说,我们将研究辍学正则化的一种变体,并将辍学与数据增强相结合。
学习已经放缓,所以我们将研究增加训练周期的数量,以便在需要时给模型足够的空间,以揭示学习曲线中的学习动态。
丢失正则化的变异性
Dropout运行得非常好,因此可能值得研究如何将Dropout应用于模型的变化。
一个可能有趣的变化是将辍学率从20%增加到25%或30%。另一个可能有趣的变化是,在模型的分类器部分中,使用丢弃从第一个块的20%、第二个块的30%,以此类推增加到完全连接层的50%的模式。
这种类型的随模型深度增加的脱落率是一种常见的模式。它是有效的,因为它强制模型中更深的层将更靠近输入的多个层正规化。
已更新为使用随模型深度增加的丢弃百分比的模式的基线模型定义如下。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
为了完整起见,下面提供了包含此更改的完整代码清单。
# baseline model with increasing dropout on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.3))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
history = model.fit(trainX, trainY, epochs=200, batch_size=64, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们可以看到性能略有提高,从固定辍学率约为83%提高到不断增加的辍学率约为84%。
> 84.690
回顾学习曲线,我们可以看到模型收敛得很好,在测试数据集上的性能可能在110到125个纪元左右停滞。与固定辍学的学习曲线相比,我们可以看到学习速度又一次进一步减慢,允许在不过度拟合的情况下对模型进行进一步改进。
这是对该模型进行研究的一个富有成效的领域,也许更多的退出层和/或更激进的退出区可能会导致进一步的改进。
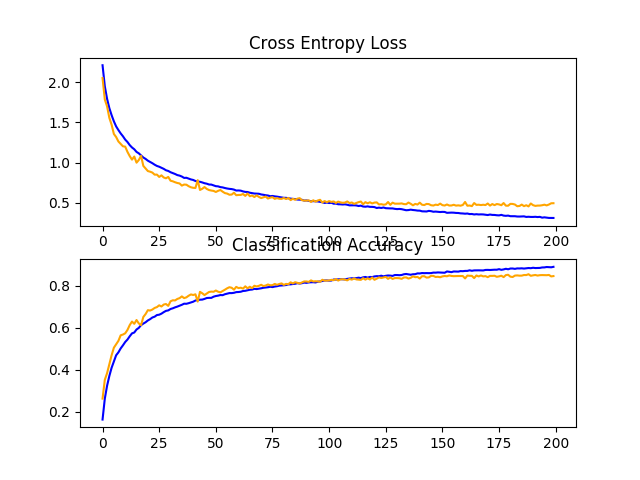 在CIFAR-10数据集上落差增大的基线模型学习曲线的直线图
在CIFAR-10数据集上落差增大的基线模型学习曲线的直线图丢失和数据增强
在上一节中,我们发现辍学和数据增强都会显著提高模型性能。
在本节中,我们可以尝试将这两个更改组合到模型中,以查看是否可以实现进一步的改进。具体地说,是否同时使用两种正则化技术比单独使用任何一种技术都会产生更好的性能。
为了完整起见,下面提供了具有固定辍学和数据增强的模型的完整代码清单。
# baseline model with dropout and data augmentation on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dropout
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# create data generator
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# prepare iterator
it_train = datagen.flow(trainX, trainY, batch_size=64)
# fit model
steps = int(trainX.shape[0] / 64)
history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=200, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们可以看到,正如我们所希望的那样,结合使用这两种正则化技术已经进一步提高了测试集上的模型性能。在这种情况下,结合大约83%的固定丢弃和大约84%的数据增强,已经导致大约85%的分类准确率的提高。
> 85.880
回顾学习曲线,我们可以看到,该模型的收敛行为也比固定丢弃和单纯的数据扩充都要好。在没有过度适应的情况下,学习速度变慢了,允许继续改进。
这一情节还表明,学习可能没有停滞,如果允许继续下去,可能会继续改善,但可能会非常温和。
如果在整个模型深度中使用不断增加的丢失率而不是固定的丢失率,则结果可能会进一步改善。
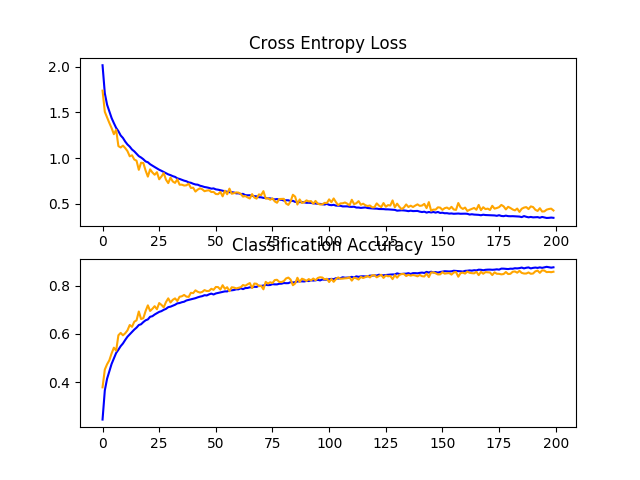 CIFAR-10数据集上带丢失和数据增强的基线模型学习曲线的直线图
CIFAR-10数据集上带丢失和数据增强的基线模型学习曲线的直线图丢弃、数据增强和批量归一化
我们可以用几种方式来扩展前面的例子。
首先,我们可以将训练周期从200个增加到400个,以给模型更多的改进机会。
下一步,我们可以添加批量规范化,以努力稳定学习,也许还可以加速学习过程。为了抵消这种加速度,我们可以通过将丢弃从固定模式更改为递增模式来增加正则化。
下面列出了更新后的模型定义。
# define cnn model def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(BatchNormalization()) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model
为了完整起见,下面提供了一个模型的完整代码清单,该模型具有不断增加的辍学率、数据扩充、批归一化和400个训练周期。
# baseline model with dropout and data augmentation on the cifar10 dataset
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dropout
from keras.layers import BatchNormalization
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.3))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
pyplot.subplot(211)
pyplot.title('Cross Entropy Loss')
pyplot.plot(history.history['loss'], color='blue', label='train')
pyplot.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
pyplot.subplot(212)
pyplot.title('Classification Accuracy')
pyplot.plot(history.history['accuracy'], color='blue', label='train')
pyplot.plot(history.history['val_accuracy'], color='orange', label='test')
# save plot to file
filename = sys.argv[0].split('/')[-1]
pyplot.savefig(filename + '_plot.png')
pyplot.close()
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# create data generator
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
# prepare iterator
it_train = datagen.flow(trainX, trainY, batch_size=64)
# fit model
steps = int(trainX.shape[0] / 64)
history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=400, validation_data=(testX, testY), verbose=0)
# evaluate model
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# learning curves
summarize_diagnostics(history)
# entry point, run the test harness
run_test_harness()
在测试工具中运行模型将在测试数据集上打印分类精度。
由于学习算法的随机性,你的特定结果可能会有所不同。
在这种情况下,我们可以看到,我们实现了模型性能的进一步提高,达到约88%的准确率,仅在丢弃和数据增强的情况下提高了约84%,在单独增加丢弃的情况下提高了约85%。
> 88.620
回顾学习曲线,我们可以看到,模型的训练在近400个时代的持续时间里显示出持续的改进。我们可以看到,在大约300个时期,测试数据集可能会略有下降,但改善的趋势仍在继续。
该模型可能受益于进一步的训练时期。
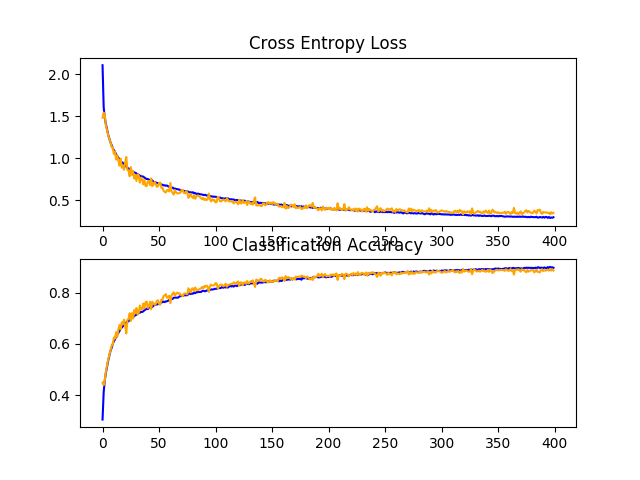 CIFAR-10数据集上具有递增丢失率、数据增大率和批量归一化的基线模型学习曲线的曲线图
CIFAR-10数据集上具有递增丢失率、数据增大率和批量归一化的基线模型学习曲线的曲线图讨论
在这一部分中,我们探索了两种方法,旨在根据我们知道已导致改进的模型更改进行扩展。
以下是调查结果的摘要:
- 基线+不断增加的辍学率:84.690%。
- 基线+丢失+数据增强:85.880%。
- 基线+不断增加的落差+数据增强+批量归一化:88.620%。
模型现在学习得很好,我们可以很好地控制学习速度,而不会过度拟合。
我们也许可以通过额外的正规化来实现进一步的改进。这可以通过在后面几层更具攻击性的辍学来实现。有可能进一步添加重量衰减可能会改进该模型。
到目前为止,我们还没有调整学习算法的超参数,比如学习率,这可能是最重要的超参数。我们可以期待随着学习率的适应性改变而得到进一步的改进,例如使用诸如Adam之类的自适应学习率技术。一旦收敛,这些类型的更改可能有助于改进模型。
如何最终确定模型并做出预测
只要我们有想法,并有时间和资源来测试它们,模型改进的过程就可能会持续下去。
在某种程度上,必须选择并采用最终的型号配置。在本例中,我们将保持简单,并使用基准模型(具有3个块的VGG)作为最终模型。
首先,我们将在整个训练数据集上拟合一个模型,并将该模型保存到文件中以供以后使用,从而最终确定我们的模型。然后,我们将加载模型并在坚持测试数据集上评估其性能,以了解所选模型在实践中的实际执行情况。最后,我们将使用保存的模型对单个图像进行预测。
保存最终模型
最终模型通常适用于所有可用的数据,例如所有训练和测试数据集的组合。
在本教程中,我们将演示仅适用于Just Training数据集的最终模型,以保持示例的简单性。
第一步是将最终模型拟合到整个训练数据集上。
# fit model model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0)
一旦合适,我们就可以通过调用模型上的save()函数将最终模型保存到H5文件中,并传入所选的文件名。
# save model
model.save('final_model.h5')
注意:保存和加载Keras模型需要在你的工作站上安装h5py库。
下面列出了将最终模型拟合到训练数据集并将其保存到文件的完整示例。
# save the final model to file
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# define cnn model
def define_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(10, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# define model
model = define_model()
# fit model
model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0)
# save model
model.save('final_model.h5')
# entry point, run the test harness
run_test_harness()
运行此示例后,你现在的当前工作目录中将有一个4.3MB的文件,名称为‘finalModel.h5’。
评估最终模型
现在,我们可以加载最终模型,并在坚持测试数据集上对其进行评估。
如果我们对向项目涉众展示所选模型的性能感兴趣,我们可能会这样做。
使用测试数据集对候选模型进行评价和选择。因此,它不会成为一个好的最终测试支持数据集。不过,在本例中,我们将使用它作为坚持数据集。
模型可以通过load_model()函数加载。
下面列出了加载保存的模型并在测试数据集上评估它的完整示例。
# evaluate the deep model on the test dataset
from keras.datasets import cifar10
from keras.models import load_model
from keras.utils import to_categorical
# load train and test dataset
def load_dataset():
# load dataset
(trainX, trainY), (testX, testY) = cifar10.load_data()
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# scale pixels
def prep_pixels(train, test):
# convert from integers to floats
train_norm = train.astype('float32')
test_norm = test.astype('float32')
# normalize to range 0-1
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# return normalized images
return train_norm, test_norm
# run the test harness for evaluating a model
def run_test_harness():
# load dataset
trainX, trainY, testX, testY = load_dataset()
# prepare pixel data
trainX, testX = prep_pixels(trainX, testX)
# load model
model = load_model('final_model.h5')
# evaluate model on test dataset
_, acc = model.evaluate(testX, testY, verbose=0)
print('> %.3f' % (acc * 100.0))
# entry point, run the test harness
run_test_harness()
运行该示例将加载保存的模型,并在坚持测试数据集中评估该模型。
计算并打印测试数据集上模型的分类精度。
在本例中,我们可以看到模型达到了大约73%的准确率,非常接近我们在评估模型作为测试工具的一部分时所看到的结果。
请注意,由于学习算法的随机性,你的特定结果可能会有所不同。
73.750
做出预测
我们可以使用保存的模型对新图像进行预测。
该模型假设新的图像是彩色的,它们已经被分割,使得一幅图像包含一个中心对象,并且图像的大小是正方形的,大小为32×32像素。
下面是从CIFAR-10测试数据集中提取的图像。你可以将其保存在当前工作目录中,文件名为‘sample_image.png’。
我们将假设这是一个全新的、不可见的图像,以所需的方式准备,并看看如何使用保存的模型来预测图像表示的整数。
对于本例,我们预期“Deer”的类为“4”。
首先,我们可以加载图像并将其大小强制为32×32像素。然后可以调整加载图像的大小,使其具有单个通道并表示数据集中的单个样本。load_image()函数实现了这一点,并将返回加载的图像,为分类做好准备。
重要的是,像素值的准备方式与在拟合最终模型时为训练数据集准备像素值的方式相同,在这种情况下,是归一化的。
# load and prepare the image
def load_image(filename):
# load the image
img = load_img(filename, target_size=(32, 32))
# convert to array
img = img_to_array(img)
# reshape into a single sample with 3 channels
img = img.reshape(1, 32, 32, 3)
# prepare pixel data
img = img.astype('float32')
img = img / 255.0
return img
接下来,我们可以像上一节那样加载模型,并调用predict_classes()函数来预测图像中的对象。
# predict the class result = model.predict_classes(img)
下面列出了完整的示例。
# make a prediction for a new image.
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.models import load_model
# load and prepare the image
def load_image(filename):
# load the image
img = load_img(filename, target_size=(32, 32))
# convert to array
img = img_to_array(img)
# reshape into a single sample with 3 channels
img = img.reshape(1, 32, 32, 3)
# prepare pixel data
img = img.astype('float32')
img = img / 255.0
return img
# load an image and predict the class
def run_example():
# load the image
img = load_image('sample_image.png')
# load model
model = load_model('final_model.h5')
# predict the class
result = model.predict_classes(img)
print(result[0])
# entry point, run the example
run_example()
运行该示例首先加载并准备图像,加载模型,然后正确预测加载的图像表示“鹿”或类“4”。
4
拓展
本节列出了一些你可能希望了解的扩展教程的想法。
- 像素缩放。探索缩放像素的替代技术,例如居中和标准化,并比较性能。
- 学习率。探索替代学习率、自适应学习率和学习率时间表,并比较性能。
- 转移学习。探索使用迁移学习,例如在此数据集上预先训练的VGG-16模型。
进一步阅读
如果你想深入了解,本节提供了更多关于该主题的资源。
文章
API接口
文章
- 分类数据集结果,此图像属于什么类别?
- CIFAR-10,维基百科。
- CIFAR-10数据集和CIFAR-100数据集。
- CIFAR-10-图像中的目标识别,卡格尔。
- 简单的CNN新闻,90%+,帕斯夸尔·乔维纳莱,卡格尔。
摘要
在本教程中,你了解了如何从头开始开发用于对象照片分类的卷积神经网络模型。
具体地说,你了解到:
- 如何开发测试工具来开发模型的健壮评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以提高学习和建模能力。
- 如何开发最终的模型,评估最终模型的性能,并使用它对新图像进行预测。

