如何用批量控制训练神经网络的稳定性
使用梯度下降来训练神经网络,其中基于训练数据集的子集计算用于更新权重的误差估计。
在误差梯度估计中使用的来自训练数据集中的样本数称为批次大小,并且是影响学习算法的动态的重要超参数。
重要的是要探索你的模型的动态,以确保你能最大限度地利用它。
在本教程中,你将发现梯度下降的三种不同风格,以及如何探索和诊断批量大小对学习过程的影响。
完成本教程后,你将了解:
- 批大小控制训练神经网络时误差梯度估计的准确性。
- 批量、随机和小批量梯度下降是学习算法的三种主要风格。
- 批次大小与学习过程的速度和稳定性之间存在着紧张关系。
教程概述
本教程分为七个部分,它们是:
- 批次大小和梯度下降。
- Keras中的随机、批次和小批次梯度下降。
- 多类分类问题。
- 批量梯度下降的MLP拟合。
- 随机梯度下降的MLP拟合。
- 小批量梯度下降的MLP拟合。
- 批量大小对模型行为的影响。
批次大小和梯度下降
神经网络的训练采用随机梯度下降优化算法。
这包括使用模型的当前状态进行预测,将预测与期望值进行比较,并使用差值作为误差梯度的估计。然后使用该误差梯度来更新模型权重,并且重复该过程。
误差梯度是统计估计。估计中使用的训练示例越多,该估计就越准确,并且越有可能以改善模型性能的方式调整网络的权重。误差梯度的改进估计的代价是,在可以计算估计之前,必须使用模型进行更多的预测,进而更新权重。
使用整个训练集的优化算法被称为批处理或确定性梯度方法,因为它们同时处理大批量的所有训练样本。
或者,使用较少的样本会导致高度依赖于所使用的特定训练示例的误差梯度的较不准确的估计。
这导致噪声估计,该噪声估计进而导致对模型权重的噪声更新,例如,具有可能完全不同的误差梯度估计的许多更新。尽管如此,这些嘈杂的更新可能会导致更快的学习,有时还会产生更健壮的模型。
一次只使用一个示例的优化算法有时称为随机方法,有时称为在线方法。术语在线通常用于示例是从连续创建的示例流中提取的情况,而不是从多次通过的固定大小的训练集中提取的情况。
在误差梯度的估计中使用的训练示例的数量是称为“批次大小”或简称为“批次”的学习算法的超参数。
批大小为32意味着在更新模型权重之前,将使用来自训练数据集中的32个样本来估计误差梯度。一个训练期意味着学习算法已经使训练数据集通过一次,其中示例被分成随机选择的“批大小”组。
历史上,将批次大小设置为训练样本的总数的训练算法称为“批次梯度下降”,将批次大小设置为1个训练示例的训练算法称为“随机梯度下降”或“在线梯度下降”。
批次大小介于两者之间的任何位置(例如,多于1个示例且少于训练数据集中的示例数量)的配置被称为“小批次梯度下降”。
- 批次渐变下降。批次大小设置为训练数据集中的样本总数。
- 随机梯度下降。批次大小设置为1。
- 迷你批次梯度下降。批次大小设置为多于一个且小于训练数据集中的示例总数。
对于速记,该算法通常被称为随机梯度下降,而不管批次大小。考虑到经常使用非常大的数据集来训练深度学习神经网络,批次大小很少设置为训练数据集的大小。
使用较小的批次大小主要有两个原因:
- 较小的批次大小有噪声,提供规则化效果和较低的泛化误差。
- 较小的批大小使在内存中(即使用GPU时)适合一批训练数据变得更容易。
第三个原因是批次大小通常设置为较小的值,例如32个示例,并且不是由从业者调整的。像32这样的小批量通常工作得很好。
[批次大小]通常在1到几百之间选择,例如[批次大小]=32是较好的默认值。
所给出的结果证实,在给定的计算成本下,在广泛的实验中,使用小批量可以获得最好的训练稳定性和泛化性能。在所有情况下,批次大小m=32或更小(通常小到m=2或m=4)都获得了最佳结果。
然而,批量大小影响模型学习的速度和学习过程的稳定性。它是一个重要的超参数,应该被深度学习实践者很好地理解和调整。
Keras 中的随机、批次和小批次梯度下降
Keras 允许你使用随机、批处理或小型批处理梯度下降来训练模型。
这可以通过在训练模型时调用fit()函数时设置batch_size 参数来实现。
让我们依次来看看每种方法。
Keras中的随机梯度下降
下面的示例将batch_size参数设置为1以进行随机渐变下降。
... model.fit(trainX, trainy, batch_size=1)
以Keras为单位的批次梯度下降
下面的示例将batch_size 参数设置为批量梯度下降的训练数据集中的样本数。
... model.fit(trainX, trainy, batch_size=len(trainX))
Keras中的Mini-Batch梯度下降
下面的示例使用batch_size参数的默认批处理大小32,对于随机梯度下降,该值大于1,而对于批处理梯度下降,该值小于训练数据集的大小。
... model.fit(trainX, trainy)
或者,可以将batch_size指定为除1或训练数据集中的样本数以外的值,例如64。
... model.fit(trainX, trainy, batch_size=64)
多类分类问题
我们将以一个小的多类分类问题为基础,演示批次大小对学习的影响。
scikit-learn类提供make_blobs()函数,该函数可用于创建具有指定数量的样本、输入变量、类和类中样本的方差的多类分类问题。
可以将问题配置为具有两个输入变量(表示点的x和y坐标)和每个组内点的标准偏差2.0。我们将使用相同的随机状态(伪随机数生成器的种子)来确保始终获得相同的数据点。
# generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
结果是我们可以建模的数据集的输入和输出元素。
为了了解问题的复杂性,我们可以在二维散点图上绘制每个点,并按类值对每个点进行着色。
下面列出了完整的示例。
# scatter plot of blobs dataset from sklearn.datasets import make_blobs from matplotlib import pyplot from numpy import where # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # scatter plot for each class value for class_value in range(3): # select indices of points with the class label row_ix = where(y == class_value) # scatter plot for points with a different color pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # show plot pyplot.show()
运行该示例将创建整个数据集的散点图。我们可以看到,2.0的标准差意味着类不是线性可分的(可以用一条线分开),这导致了许多模糊点。
这是可取的,因为它意味着问题不是微不足道的,并将允许神经网络模型找到许多不同的“足够好”的候选解决方案。

批量梯度下降的MLP拟合
我们可以开发一个多层感知器模型(MLP)来解决上一节描述的多类分类问题,并使用批量梯度下降来训练它。
首先,我们需要对目标变量进行一次热编码,将整数类值转换为二进制向量。这将允许模型预测每个示例属于这三个类别中每一个的概率,从而在训练模型时在预测和上下文中提供更多细微差别。
# one hot encode output variable y = to_categorical(y)
接下来,我们将把1000个样本的训练数据集分割成每个500个样本的训练和测试数据集。
这种均匀的分割将允许我们评估和比较模型上不同批次大小配置的性能及其性能。
# split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:]
我们将为数据集中的两个变量定义一个具有输入层的MLP模型,该输入层需要两个输入变量。
该模型将有一个具有50个节点的单一隐含层,以及一个校正的线性激活函数和随机权重初始化。最后,输出层具有3个节点,以便对这三个类和Softmax激活函数进行预测。
# define model model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax'))
采用随机梯度下降法对模型进行优化,并使用分类交叉熵计算模型在训练过程中的误差。
在本例中,我们将使用“批处理梯度下降”,这意味着批处理大小将设置为训练数据集的大小。模型将适用于200个训练周期,测试数据集将用作验证集,以便在训练期间监控模型在抗拒集上的性能。
其效果将是权重更新之间的时间更长,我们预计比其他批次大小的训练速度更快,梯度的估计更稳定,这应该会导致模型在训练期间的性能更稳定。# compile model
opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=len(trainX))
一旦模型合适,就会在训练和测试数据集上评估和报告性能。
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
创建一个线条图,显示每个训练时段模型的训练和测试集精度。
这些学习曲线提供了三个方面的指示:模型学习问题的速度有多快,它学习问题的程度有多好,以及在训练期间更新模型的噪音有多大。
# plot training history pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show()
将这些元素捆绑在一起,完整的示例如下所示。
# mlp for the blobs problem with batch gradient descent
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=len(trainX))
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot training history
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
运行该示例首先报告模型在列车和测试数据集上的性能。
考虑到学习算法的随机性,你的特定结果可能会有所不同;请考虑将该示例运行几次。
在这种情况下,我们可以看到训练集和测试集之间的性能相似,分别为81%和83%。
Train: 0.816, Test: 0.830
在训练(蓝色)和测试(橙色)数据集上创建模型分类精度的线状图。我们可以看到,模型学习这个问题的速度相对较慢,在大约100个时期之后收敛到一个解,之后模型性能的变化很小。

随机梯度下降的MLP拟合
可以更新来自上一节的批量梯度下降的示例,以取而代之使用随机梯度下降。
这需要将批大小从训练数据集的大小更改为1。
# fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=1)
随机梯度下降要求模型进行预测,并针对每个训练样本更新权重。与批量梯度下降相比,这具有显著减慢训练过程的效果。
这种改变的预期是模型学习得更快,并且模型的改变是有噪声的,进而导致在训练时期内有噪声的性能。
下面列出了此更改的完整示例。
# mlp for the blobs problem with stochastic gradient descent
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=1)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot training history
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
运行该示例首先报告模型在训练和测试数据集上的性能。
考虑到学习算法的随机性,你的特定结果可能会有所不同;请考虑将该示例运行几次。
在这种情况下,我们可以看到训练集和测试集之间的性能相似,大约60%的准确率,但比使用批量梯度下降要差得多(大约20个百分点)。
至少对于这个问题以及所选择的模型和模型配置而言,随机(在线)梯度下降是不合适的。
Train: 0.612, Test: 0.606
在训练(蓝色)和测试(橙色)数据集上创建模型分类精度的线状图。
该图显示了使用所选配置的培训过程的不稳定性质。较差的性能和模型的剧烈变化表明,在每个训练示例之后用于更新权重的学习率可能太大,较小的学习率可能会使学习过程更加稳定。

我们可以通过重新运行符合随机梯度下降和较小学习率的模型来测试这一点。例如,我们可以将学习率降低一个数量级,从0.01降到0.001。
# compile model opt = SGD(lr=0.001, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
为了完整起见,下面提供了包含此更改的完整代码清单。
# mlp for the blobs problem with stochastic gradient descent
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.001, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=1)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot training history
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
运行此示例讲述了一个非常不同的情景。
考虑到学习算法的随机性,你的特定结果可能会有所不同;请考虑将该示例运行几次。
报告的性能得到了极大的提高,使用批量梯度下降在训练和测试集上实现了与FIT相当的分类精度。
Train: 0.816, Test: 0.824
线条图显示了预期的行为。也就是说,与批量梯度下降相比,该模型快速学习问题,在大约25个历元内跃升到约80%的准确率,而不是在使用批量梯度下降时看到的100个历元。我们本可以在50号纪元而不是200号纪元停止训练,因为训练速度更快。
这并不令人惊讶。在批量梯度下降的情况下,100个历元包括100个误差估计和100个权重更新。在随机梯度下降中,涉及25个历元(500*25)或12,500个权重更新,提供了关于如何改进模型的10倍以上的反馈,尽管有更多的噪声反馈。
线图还显示,与批量梯度下降的动态性能相比,训练和测试性能在训练期间保持可比,在测试集上的性能略好,并在整个训练过程中保持不变。
与批量梯度下降不同,我们可以看到噪声更新在整个训练过程中都会导致噪声性能。模型中的这种方差意味着选择使用哪个模型作为最终模型可能具有挑战性,而不是批量梯度下降,在批量梯度下降中性能稳定,因为模型已经收敛。

这个例子突出了批次大小和学习率之间的重要关系。也就是说,对模型的更多噪声更新需要更小的学习率,而对误差梯度的更少噪声更准确的估计可以更自由地应用于模型。我们可以概括为以下几点:
- 批量梯度下降:使用相对较大的学习率和较多的训练周期。
- 随机梯度下降:使用相对较小的学习率和较少的训练周期。
小批量梯度下降法提供了一种可供选择的方法。
小批量梯度下降的MLP拟合
使用随机梯度下降和调整学习率的另一种选择是保持学习率恒定并改变批次大小。
实际上,这意味着我们在每次估计误差梯度时指定要应用于权重的学习速率或变化量,但是基于用于估计它的样本数量来改变梯度的精度。
将学习率保持在0.01,就像我们对批处理梯度下降所做的那样,我们可以将批处理大小设置为32,这是广泛采用的默认批处理大小。
# fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=32)
我们期望以更大的学习率获得随机梯度下降的一些好处。
下面列出了此修改的完整示例。
# mlp for the blobs problem with minibatch gradient descent
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=32)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot training history
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
运行示例时,训练集和测试集的性能相似,与降低学习率后的批量梯度下降和随机梯度下降相当。
Train: 0.832, Test: 0.812
直线图显示了随机梯度下降和批量梯度下降的动态。具体地说,该模型学习速度快,更新噪声大,但在运行接近尾声时也更稳定,比随机梯度下降更稳定。
保持学习速率不变并改变批量大小可以让你在这两种方法中发挥最好的作用。
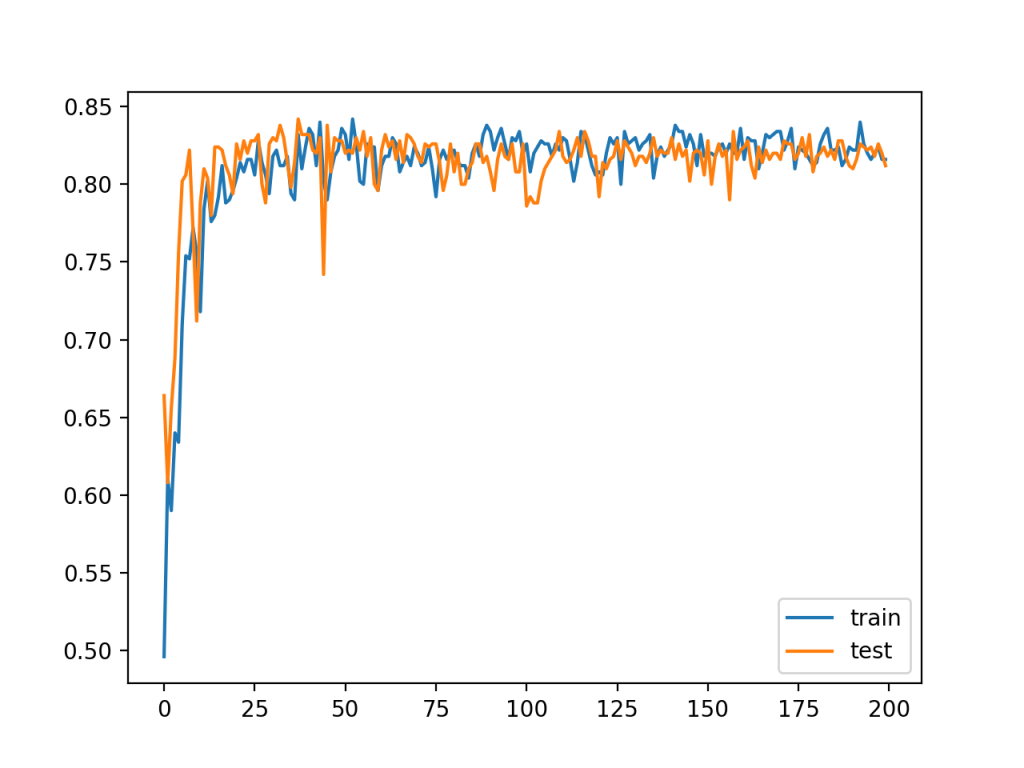 小批量梯度下降MLP拟合的训练分类精度直线图及测试集
小批量梯度下降MLP拟合的训练分类精度直线图及测试集批量大小对模型行为的影响
我们可以用不同的批次大小来改装模型,并审查批次大小的变化对学习速度、学习过程中的稳定性以及对最终结果的影响。
首先,我们可以清理代码并创建一个函数来准备数据集。
# prepare train and test dataset def prepare_data(): # generate 2d classification dataset X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # one hot encode output variable y = to_categorical(y) # split into train and test n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy
接下来,我们可以创建一个函数来拟合具有给定批次大小的问题的模型,并在训练和测试数据集上绘制分类精度的学习曲线。
# fit a model and plot learning curve
def fit_model(trainX, trainy, testX, testy, n_batch):
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=n_batch)
# plot learning curves
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.title('batch='+str(n_batch), pad=-40)
最后,我们可以使用一套不同的批次大小来评估模型行为,同时保持模型的其他所有内容不变,包括学习率。
# prepare dataset trainX, trainy, testX, testy = prepare_data() # create learning curves for different batch sizes batch_sizes = [4, 8, 16, 32, 64, 128, 256, 450] for i in range(len(batch_sizes)): # determine the plot number plot_no = 420 + (i+1) pyplot.subplot(plot_no) # fit model and plot learning curves for a batch size fit_model(trainX, trainy, testX, testy, batch_sizes[i]) # show learning curves pyplot.show()
结果将是一个具有8个不同批次大小的8个模型行为曲线图的图。
将这些结合在一起,完整的示例如下所示。
# mlp for the blobs problem with minibatch gradient descent with varied batch size
from sklearn.datasets import make_blobs
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import SGD
from keras.utils import to_categorical
from matplotlib import pyplot
# prepare train and test dataset
def prepare_data():
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
return trainX, trainy, testX, testy
# fit a model and plot learning curve
def fit_model(trainX, trainy, testX, testy, n_batch):
# define model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(3, activation='softmax'))
# compile model
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0, batch_size=n_batch)
# plot learning curves
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.title('batch='+str(n_batch), pad=-40)
# prepare dataset
trainX, trainy, testX, testy = prepare_data()
# create learning curves for different batch sizes
batch_sizes = [4, 8, 16, 32, 64, 128, 256, 450]
for i in range(len(batch_sizes)):
# determine the plot number
plot_no = 420 + (i+1)
pyplot.subplot(plot_no)
# fit model and plot learning curves for a batch size
fit_model(trainX, trainy, testX, testy, batch_sizes[i])
# show learning curves
pyplot.show()
运行该示例将创建一个图,其中包含8个线图,显示使用小批量梯度下降时不同批次大小的模型的列车和测试集的分类精度。
结果表明,小批量的学习速度一般较快,但学习过程不稳定,分类精度的方差较高。较大的批次大小减慢了学习过程,但最后阶段导致收敛到更稳定的模型,例如分类精度的方差较低。

进一步阅读
如果你想深入了解,本节提供了更多关于该主题的资源。
文章
论文
书籍
文章
摘要
在本教程中,你了解了梯度下降的三种不同风格,以及如何探索和诊断批量大小对学习过程的影响。
具体地说,你了解到:
- 批大小控制训练神经网络时误差梯度估计的准确性。
- 批量、随机和小批量梯度下降是学习算法的三种主要风格。
- 批次大小与学习过程的速度和稳定性之间存在着紧张关系。

