在Keras中显示深度学习模型训练历史
通过观察神经网络和深度学习模型在训练过程中随时间推移的性能,你可以了解到更多关于神经网络和深度学习模型的知识。
Keras是一个功能强大的Python库,它为创建深度学习模型提供了一个干净的接口,并封装了更具技术性的TensorFlow和Theano后端。
在这篇文章中,你将了解如何在使用Keras进行Python训练期间查看和可视化深度学习模型随时间推移的性能。
我们开始吧。
访问Keras中的模型训练历史记录
Keras在训练深度学习模型时提供了注册回调的功能。
训练所有深度学习模型时注册的默认回调之一是历史回调。它记录每个时期的训练指标。这包括验证数据集的损失和准确度(对于分类问题)以及损失和准确度(如果设置了一个数据集的话)。
历史对象是从调用用于训练模型的Fit()函数返回的。指标存储在返回对象的历史成员的字典中。
例如,你可以在训练模型后使用以下代码片段列出在历史记录对象中收集的指标:
... # list all data in history print(history.history.keys())
例如,对于针对验证数据集的分类问题进行训练的模型,这可能会生成以下列表:
['accuracy', 'loss', 'val_accuracy', 'val_loss']
我们可以使用历史对象中收集的数据来创建绘图。
曲线图可以提供有关模型训练的有用信息,例如:
- 它在epoch(斜率)上的收敛速度。
- 模型是否已经收敛(直线的平台期)。
- 模式是否可以过度学习训练数据(验证线的音调变化)。
还有更多。
在Keras中可视化模型训练历史。
我们可以从收集的历史数据中创建曲线图。
在下面的例子中,我们创建了一个小型网络来模拟皮马印第安人糖尿病发作的二进制分类问题。这是UCI机器学习存储库提供的一个小数据集。你可以下载数据集,并将其保存为当前工作目录中的pima-indians-diabetes.csv(更新:从此处下载)。
该示例收集模型训练返回的历史记录,并创建两个图表:
- 训练和验证数据集在训练时段上的精确度曲线图。
- 训练和验证数据集在训练期间的损失图。
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
图表如下所示。按照惯例,验证数据集的历史记录被标记为test,因为它确实是模型的测试数据集。
从精确度图中我们可以看到,模型可能需要更多的训练,因为在过去的几个时期,两个数据集的精确度趋势仍在上升。我们还可以看到,模型还没有过度学习训练数据集,在两个数据集上显示出相当的技能。
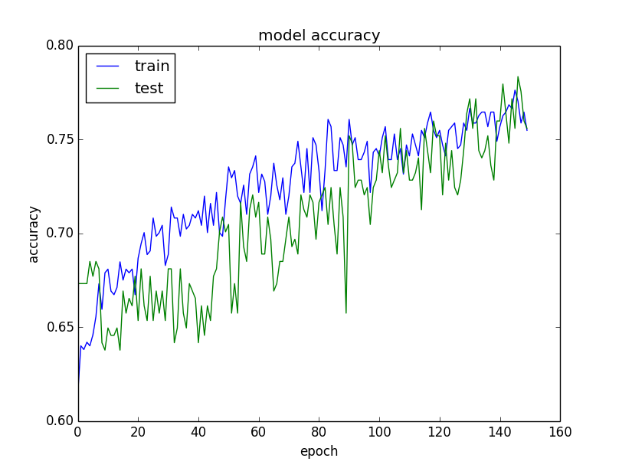 训练和验证数据集上模型精度的绘图
训练和验证数据集上模型精度的绘图从损失图中可以看出,该模型在训练数据集和验证数据集(标记为test)上具有相当的性能。如果这些平行的情节开始一致地离开,这可能是一个在更早的时代停止训练的迹象。
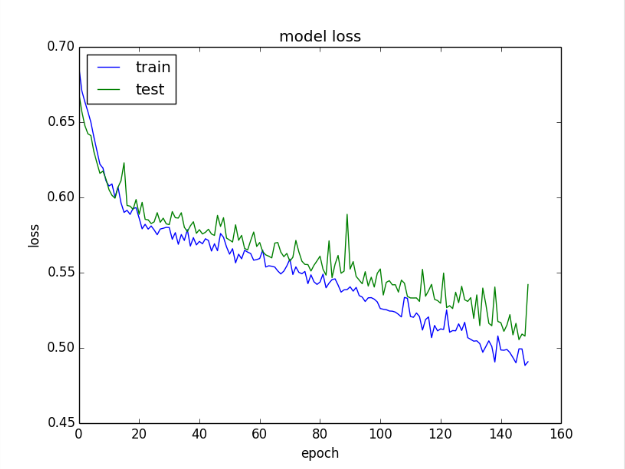 训练和验证数据集上的模型损失曲线图
训练和验证数据集上的模型损失曲线图
摘要
在这篇文章中,你发现了在深度学习模型的训练过程中收集和审查指标的重要性。
你了解了Keras中的历史回调,以及如何始终通过调用Fit()函数返回历史回调以训练模型。你学习了如何从训练期间收集的历史数据创建打印。

